
Los sistemas robóticos autónomos y autoguiados han captado gran atención y se han utilizado en sectores como la exploración espacial, el transporte, la automatización industrial y la defensa. Sin embargo, los robots sociales de interiores, si bien son expertos en sortear obstáculos en espacios reducidos, a menudo carecen de capacidades de navegación avanzadas. La implementación de la navegación autónoma para su compañero robótico, que facilita tareas como el desplazamiento autónomo a una estación de carga o la navegación interior guiada con precisión, exige la aplicación de algoritmos sofisticados y tecnologías de vanguardia. En este blog, exploraremos el ámbito del SLAM y su papel fundamental para facilitar la autoguiación en robots sociales de interiores.
SLAM para navegación robótica
SLAM, o Localización y Mapeo Simultáneos [1,2], es una técnica computacional que permite a un robot o vehículo construir un mapa de un entorno desconocido a la vez que determina su propia posición dentro de dicho entorno, utilizando datos de sensores y algoritmos probabilísticos. Al integrar datos de sensores como mediciones visuales, de profundidad o de alcance, los algoritmos SLAM generan un mapa del entorno del robot y determinan su ubicación precisa dentro de él. Con SLAM, un robot puede navegar y explorar entornos desconocidos o parcialmente conocidos construyendo un mapa de forma incremental a medida que se desplaza y localizándose simultáneamente en él. Esta capacidad le permite planificar y ejecutar rutas de navegación de forma autónoma, evitar obstáculos y alcanzar sus destinos.
Curiosamente, SLAM es un clásico problema de la gallina y el huevo debido a la dependencia circular entre sus dos pasos integrales: mapeo y localización. El mapeo requiere conocer la posición del robot para ubicar con precisión los puntos de referencia en el mapa, mientras que la localización se basa en un mapa para estimar la posición del robot. En términos más simples, para crear un mapa, el robot necesita conocer su ubicación, pero para determinarla, necesita un mapa. Esta dependencia circular dificulta resolver simultáneamente el mapeo y la localización.
Para superar este desafío, los algoritmos SLAM emplean métodos probabilísticos para estimar iterativamente la posición del robot y actualizar el mapa. Inicialmente, el robot asume su posición y construye un mapa preliminar. A medida que se mueve y recopila más datos de sensores, refina su estimación de posición y actualiza el mapa en consecuencia. Este proceso iterativo continúa, y el robot mejora gradualmente tanto sus estimaciones de mapa como de localización. Al refinar iterativamente las estimaciones de mapa y localización, los algoritmos SLAM pueden romper la dependencia del huevo y la gallina y converger hacia una representación más precisa del entorno y de la posición del robot en él.
La arquitectura SLAM comprende un front-end y un back-end como se muestra en la siguiente figura.

El front-end de SLAM se encarga del procesamiento en tiempo real de los datos de los sensores y de la extracción de información relevante para el mapeo y la localización. Principalmente, el front-end realiza las siguientes tareas:
Extracción de características : El frontend extrae características distintivas de los datos de los sensores, como puntos clave o puntos de referencia, que pueden rastrearse de forma fiable a lo largo del tiempo. Estas características sirven como puntos de referencia para los procesos de mapeo y localización.
Asociación de datos : El front-end asocia las características extraídas en diferentes mediciones y fotogramas del sensor. Identifica correspondencias entre características en fotogramas consecutivos, estableciendo la relación temporal entre ellas.
Seguimiento : El frontend rastrea las características extraídas y estima su movimiento a lo largo del tiempo. Predice la posición de las características en fotogramas posteriores y determina cómo se mueven, lo que permite estimar el movimiento del robot y facilita un mapeo y una localización precisos.
De esta forma, el front-end se centra esencialmente en tareas de percepción y seguimiento en tiempo real, aportando información valiosa para el back-end.
El backend de SLAM implica la optimización y el refinamiento de las poses estimadas del robot y la creación de una representación cartográfica consistente. El backend utiliza la información del frontend y realiza comprobaciones de consistencia global. Las tareas clave que realiza el backend incluyen:
Optimización de poses : El backend refina las poses estimadas del robot basándose en los datos recopilados por los sensores, las correspondencias de características y los modelos de movimiento. Optimiza las poses mediante técnicas como el ajuste de paquetes para minimizar errores y mejorar la precisión de la trayectoria estimada.
Optimización del mapa : El back-end refina la representación del mapa (mediante la técnica Máximo A Posteriori) incorporando las poses y las mediciones de características refinadas. Ajusta el mapa para alinearlo con las trayectorias estimadas y reduce las inconsistencias o errores.
Además, la detección de cierres de bucle, que se produce cuando el robot vuelve a visitar un área previamente mapeada, se realiza como un proceso independiente que se ejecuta a una velocidad mucho menor que la de la cámara. Los cierres de bucle se detectan al reconocer similitudes o coincidencias entre diferentes partes del mapa. Los resultados de los cierres de bucle se incorporan como información adicional al componente de estimación y optimización de MAP del backend y ayudan a corregir errores, refinar el mapa y mejorar la precisión general de SLAM.
Por lo tanto, el back-end se centra en la optimización global y en mantener la coherencia entre las poses estimadas y el mapa generado. En resumen, el front-end de SLAM gestiona la percepción en tiempo real, la extracción de características, la asociación de datos y el seguimiento. El back-end realiza la optimización, refina las poses y los mapas, e incorpora cierres de bucle para lograr la coherencia global. Estos dos componentes trabajan conjuntamente para permitir la localización y el mapeo simultáneos para la navegación autónoma.
Visual SLAM (Localización y Mapeo Simultáneos) es una técnica que utiliza visión artificial y datos de sensores visuales, como imágenes o fotogramas de vídeo, para crear simultáneamente un mapa del entorno y estimar la posición del robot o la cámara en él. Mediante la extracción de características visuales, el seguimiento de su movimiento a lo largo del tiempo y el uso de algoritmos probabilísticos, Visual SLAM permite a los sistemas autónomos navegar y construir un mapa basado en información visual. Los puntos de referencia que indican objetos de interés se rastrean a través de fotogramas sucesivos de la cámara y su posición 3D se estima mediante la triangulación de puntos característicos. Simultáneamente, esta información también se utiliza para aproximar la pose de la cámara. Esta información se utiliza posteriormente en la fase de back-end para ubicar el robot en relación con su entorno. Visual SLAM tiene aplicaciones en robótica, realidad aumentada, vehículos autónomos y reconstrucción 3D.
Desafíos de la navegación en interiores del hogar
Realizar SLAM visual en interiores de una vivienda es todo un reto debido a la complejidad y dinámica del entorno. En un entorno industrial, se pueden utilizar códigos QR y etiquetas Aruco para facilitar el proceso de localización. Sin embargo, esto no es posible en el ámbito doméstico. Algunos desafíos clave específicos de la navegación en interiores son:
Falta de características visuales : Los entornos interiores pueden presentar características visuales limitadas o escasas en comparación con los exteriores. Las paredes lisas, los patrones repetitivos y las texturas homogéneas pueden dificultar que los sistemas SLAM visuales extraigan características distintivas, lo que genera dificultades de seguimiento y errores en la estimación de la pose.
Entorno dinámico : Las viviendas son entornos dinámicos con límites y trayectorias irregulares, ya que los objetos pueden moverse o aparecer o desaparecer con el tiempo. Los muebles, las personas y las mascotas pueden obstruir el campo de visión o introducir cambios inesperados, lo que pone en peligro la estabilidad y la precisión de los algoritmos visuales SLAM.
Variaciones de iluminación : Las condiciones de iluminación en interiores pueden variar significativamente, incluyendo cambios en el brillo, las sombras o las fuentes de luz artificial. Estas variaciones pueden afectar la calidad y la consistencia de los datos del sensor visual, lo que afecta la detección de características, el seguimiento y la estimación de la pose.
Campo de visión limitado : En espacios interiores reducidos, el campo de visión de la cámara puede verse restringido, lo que dificulta la observación parcial del entorno. Una visibilidad limitada puede dificultar la extracción de suficientes características y la estimación precisa de la posición y la orientación del robot.
Oclusiones de sensores : Los objetos o muebles del hogar pueden obstruir la visión de los sensores visuales, dificultando la detección y el seguimiento de las características visuales. Las oclusiones pueden alterar la correspondencia entre las características y afectar la precisión de la estimación de la postura.
Estimación de escala : Sin información adicional de profundidad, estimar la escala con precisión en interiores puede ser difícil. Esto puede generar ambigüedad en la escala, dificultando la representación precisa del tamaño o la distancia de los objetos en el mapa generado.
Entornos homogéneos : Algunas zonas de una vivienda, como pasillos largos o habitaciones con características similares, pueden tener una apariencia homogénea. Esta falta de diversidad visual puede dificultar que el sistema SLAM distinga entre diferentes ubicaciones o identifique correctamente los cierres de bucle.
Movimientos impredecibles : Al ser un robot social, es muy probable que la interacción social con él interfiera en su proceso de mapeo y/o navegación. Los algoritmos SLAM están diseñados de forma robusta para mitigar estas situaciones; sin embargo, esto podría comprometer la precisión del algoritmo.
Abordar estos desafíos suele requerir el desarrollo de métodos robustos de extracción de características, algoritmos de seguimiento sofisticados, técnicas de fusión de sensores (como la incorporación de sensores de profundidad o IMU), la adaptación a condiciones de iluminación cambiantes y el manejo de oclusiones. Además, aprovechar el conocimiento previo del entorno o incorporar sensores adicionales puede mejorar el rendimiento y la fiabilidad de la navegación en interiores con SLAM visual.
Bots sociales versus aspiradoras robot
Mapear el entorno para robots sociales o de compañía es más difícil que para las aspiradoras robot debido a los entornos dinámicos y complejos en los que operan, sus mayores requisitos de interacción, sus diversas capacidades de tarea, su adaptabilidad centrada en el usuario y la necesidad de garantizar la seguridad y las consideraciones sociales durante la navegación. Las aspiradoras robot pueden mapear su entorno mientras barren o fregan, ya que no suelen ser molestadas. Por otro lado, mapear el entorno en robots sociales es mucho más difícil, ya que operan en entornos no controlados y requieren capacidades avanzadas de percepción y comprensión para interactuar con objetos y personas. Requieren un mapeo personalizado para adaptarse a las preferencias individuales del usuario y ofrecer una gama de tareas más allá de la navegación y la limpieza. Un robot podría ser levantado y desplazado durante el proceso de creación del mapa. Los robots sociales también experimentan un mayor desgaste de las lentes de la cámara, los sensores y los codificadores de las ruedas, lo que puede afectar la integridad del SLAM. Por último, pero no menos importante, la tecnología utilizada para el SLAM debe ser rentable para cumplir con el precio que los consumidores están dispuestos a pagar.
Marco de autonavegación en Miko
En Miko, trabajamos en la integración de SLAM visual inercial para nuestra futura generación de robots acompañantes con el fin de abordar los desafíos mencionados. El SLAM visual inercial combina datos de sensores visuales de cámaras con mediciones inerciales de una IMU (Unidad de Medición Inercial). Al fusionar la información de ambos sensores, el SLAM visual inercial logra una estimación precisa y robusta de la postura del robot y crea un mapa del entorno. Aprovecha las características visuales para una percepción detallada del entorno e integra mediciones inerciales para una estimación robusta del movimiento, lo que lo hace valioso para aplicaciones como la robótica, la realidad aumentada, los vehículos autónomos y la realidad virtual.
El SLAM visual-inercial generalmente implica los siguientes pasos:
Calibración del sensor : calibre la cámara y la IMU para obtener mediciones precisas.
Inicialización : establecer una estimación de la postura inicial utilizando características visuales y datos inerciales.
Seguimiento de características y odometría inercial : realice un seguimiento de las características visuales y calcule el movimiento del robot utilizando mediciones inerciales.
Fusión visual-inercial : fusiona datos visuales e inerciales para una estimación de pose optimizada.
Mapeo : construya un mapa utilizando características rastreadas y poses estimadas.
Detección de cierre de bucle y optimización de mapas : identifique ubicaciones revisadas para corregir errores y refine poses y posiciones de características para una mejor consistencia del mapa.
Actualizaciones de localización y mapeo : actualice continuamente poses, mapas e incorpore nuevos datos.
Estos pasos proporcionan una descripción general concisa del proceso iterativo en SLAM visual-inercial, que abarca la calibración, la inicialización, la estimación de movimiento, la fusión, el mapeo, el cierre de bucle, la optimización y las actualizaciones continuas involucradas en la localización y el mapeo simultáneos.
En la Figura 2 se muestra un diagrama de bloques del SLAM inercial visual.
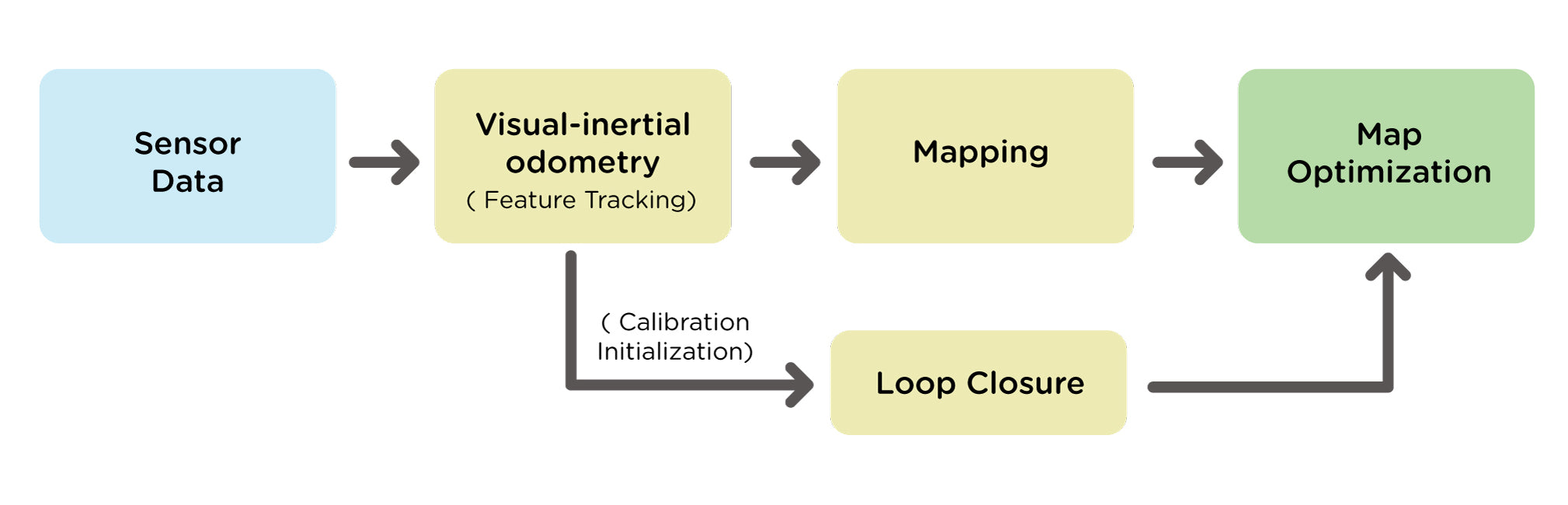
Miko utiliza una cámara monocular, una unidad de medición inercial (IMU) y codificadores de rueda para capturar datos que se resumen en modelos. Los fotogramas sucesivos de la cámara monocular, junto con las lecturas del giroscopio (velocidad angular en los tres ejes) de la IMU, se utilizan para estimar la pose de la cámara, detectar puntos de referencia y rastrear el movimiento mediante odometría inercial visual (VIO) (véase la Figura 3). Además, el codificador de rueda (Miko utiliza un codificador de cuadratura magnética) se utiliza para determinar el desplazamiento lineal (en los ejes x e y) y angular (alrededor del eje z) del robot contando las rotaciones de las ruedas. Esta información se utiliza para optimizar y corregir la estimación de la pose VIO para obtener la profundidad y la escala adecuadas.

Los filtros de back-end y las etapas de reconstrucción (véase la Figura 3) refinan la salida VIO para generar trayectorias de robot totalmente optimizadas y un mapa de cuadrícula de ocupación detallado (mostrado en la Figura 4). Este mapa de cuadrícula de ocupación se utiliza para comprender el entorno y guiar al robot. El cierre del bucle realiza correcciones y elimina las desviaciones acumuladas, estimando si el robot ha regresado a su posición original.

Figura 4: Cuadrícula de ocupación 2D: los puntos de la cuadrícula ocupados son negros, los desocupados son blancos y los puntos de la cuadrícula desconocidos son grises ( Creative Commons — Atribución 4.0 Internacional — CC BY 4.0 )
Resumen
La tecnología SLAM (Localización y Mapeo Simultáneos) ha revolucionado el panorama de los bots sociales autónomos para interiores. Al aprovechar el poder de los sensores visuales y las mediciones inerciales, estos bots pueden navegar en interiores, mapear su entorno e interactuar con humanos de forma personalizada e interactiva. A medida que las técnicas SLAM siguen avanzando, podemos esperar bots más inteligentes con capacidades mejoradas para interacciones educativas e interactivas.
Referencias
[1] Cadena, Cesar y Carlone, Luca y Carrillo, Henry y Latif, Yasir y Scaramuzza, Davide y Neira, Jose y Reid, Ian y Leonard, John. (2016). Localización y mapeo simultáneos: Presente, futuro y la era de la percepción robusta. IEEE Transactions on Robotics. 32. 10.1109/TRO.2016.2624754.
[2] Bienvenido a Conocimientos básicos sobre SLAM visual: de la teoría a la práctica, por Xiang Gao, Tao Zhang, Qinrui Yan y Yi Liu












