
Autonomous and self-navigating robotic systems have garnered significant attention and utilization in sectors spanning space exploration, transportation, industrial automation, and defense. Nonetheless, indoor social robots, while adept at navigating obstacles within constrained spaces, often fall short of advanced navigation capabilities. The realization of autonomous navigation for your robotic companion, facilitating tasks like autonomous traversal to a charging station or precision-guided indoor navigation, mandates the application of sophisticated algorithms and state-of-the-art technologies. In this blog, we shall explore the realm of SLAM and its pivotal role in enabling self-navigation in indoor social robots.
SLAM for Robotic Navigation
SLAM, or Simultaneous Localization and Mapping [1,2], is a computational technique that enables a robot or vehicle to construct a map of an unknown environment while simultaneously determining its own position within that environment, using sensor data and probabilistic algorithms. By integrating sensor data such as visual, depth, or range measurements, SLAM algorithms generate a map of the robot's surroundings and determine its precise location within that map. With SLAM, a robot can navigate and explore unknown or partially known environments by incrementally building a map as it moves and simultaneously localizing itself within that map. This capability allows the robot to autonomously plan and execute navigation paths, avoid obstacles and reach desired destinations.
Interestingly, SLAM is a classic “chicken-and-egg” problem due to the circular dependency between its two integral steps of mapping and localization. Mapping requires knowledge of the robot's position to accurately place landmarks in the map, while localization relies on a map to estimate the robot's position. In simpler terms, to create a map, the robot needs to know its location, but to determine its location, the robot needs a map. This circular dependency makes it challenging to solve both mapping and localization simultaneously.
To overcome this challenge, SLAM algorithms employ probabilistic methods to iteratively estimate the robot's position and update the map. Initially, the robot makes assumptions about its position and builds a preliminary map. As it moves and collects more sensor data, it refines its position estimate and updates the map accordingly. This iterative process continues, with the robot gradually improving both its map and localization estimates. By iteratively refining the map and localization estimates, SLAM algorithms can break the chicken and egg dependency and converge to a more accurate representation of the environment and the robot's position within it.
The SLAM architecture comprises a front-end and a back-end as shown in the figure below.

The front-end of SLAM is responsible for the real-time processing of sensor data and extracting relevant information for mapping and localization. Primarily, the front-end performs the following tasks:
Feature Extraction: The front-end extracts distinctive features from sensor data, such as key points or landmarks, that can be reliably tracked over time. These features serve as reference points for the mapping and localization processes.
Data Association: The front-end associates the extracted features across different sensor measurements and frames. It identifies correspondences between features in consecutive frames, establishing the temporal relationship between them.
Tracking: The front-end tracks the extracted features and estimates their motion over time. It predicts the positions of the features in subsequent frames and determines how they move, enabling the estimation of the robot's movement and aiding in accurate mapping and localization.
Thus, the front-end essentially focuses on real-time perception and tracking tasks, providing valuable information for the back-end.
The back-end of SLAM involves the optimization and refinement of the estimated robot poses and the creation of a consistent map representation. The back-end utilizes the information from the front-end and performs global consistency checks. The key tasks performed by the back-end include:
Pose Optimization: The back-end refines the estimated robot poses based on the collected sensor data, feature correspondences, and motion models. It optimizes the poses using techniques like bundle adjustment to minimize errors and improve the accuracy of the estimated trajectory.
Map Optimization: The back-end refines the map representation (using the Maximum A Posteriori technique) by incorporating the refined poses and feature measurements. It adjusts the map to align with the estimated trajectories and reduces inconsistencies or errors in the map.
In addition, detection of loop closures, which occurs when the robot revisits a previously mapped area, is performed as an independent process running at a much lower rate than the camera frame rate. Loop closures are detected by recognizing similarities or matching features between different parts of the map. Loop closure results are fed back as an additional input to the MAP estimation and optimization component of the backend and help in correcting errors, refining the map, and improving the overall accuracy of SLAM.
Thus, the back-end focuses on global optimization and maintaining consistency in the estimated poses and the generated map. In summary, the front-end of SLAM handles real-time perception, feature extraction, data association, and tracking. The back-end performs optimization, refines poses and maps, and incorporates loop closures for global consistency. These two components work together to enable simultaneous localization and mapping for autonomous navigation.
Visual SLAM (Simultaneous Localization and Mapping) is a technique that uses computer vision and visual sensor data, like images or video frames, to simultaneously create a map of the environment and estimate the robot's or camera's position within it. By extracting visual features, tracking their movement over time, and utilizing probabilistic algorithms, visual SLAM enables autonomous systems to navigate and build a map based on visual information. Set points denoting objects of interest are tracked through successive camera frames and their 3D position is estimated using feature point triangulation. Simultaneously, this information is also used to approximate the camera pose. This information is then used in the back-end stage to locate the robot relative to its environment. Visual SLAM finds applications in robotics, augmented reality, autonomous vehicles, and 3D reconstruction.
Challenges of Indoor Navigation within the Home
Performing visual SLAM indoors within a home is quite challenging due to the complexity and dynamics of the environment. In an industrial setting, QR codes and Aruco tags can be used to aid the localization process. This is however not possible within the home environment. Some key challenges specific to indoor navigation are:
Lack of Visual Features: Indoor environments may have limited or sparse visual features compared to outdoor environments. Plain walls, repetitive patterns, and homogeneous textures can make it difficult for visual SLAM systems to extract distinctive features, resulting in tracking difficulties and pose estimation errors.
Dynamic Environment: Homes are dynamic environments with irregular boundaries and paths as objects can be moved or appear/disappear over time. Furniture, people, and pets can obstruct the field of view or introduce unexpected changes, challenging the stability and accuracy of visual SLAM algorithms.
Lighting Variations: Indoor lighting conditions can vary significantly, including changes in brightness, shadows, or artificial lighting sources. These variations can impact the quality and consistency of visual sensor data, affecting feature detection, tracking, and pose estimation.
Limited Field of View: In confined indoor spaces, the field of view of the camera may be restricted, leading to partial observability of the environment. Limited visibility can hinder the ability to extract sufficient features and accurately estimate the robot's position and orientation.
Sensor Occlusions: Objects or furniture within the home can occlude the view of the visual sensors, obstructing the detection and tracking of visual features. Occlusions can disrupt feature correspondences and impact the accuracy of pose estimation.
Scale Estimation: Without additional depth information, estimating accurate scale in indoor environments can be challenging. This can result in scale ambiguity, making it difficult to accurately represent object sizes or distances in the generated map.
Homogeneous Environments: Some areas of a home, such as long hallways or rooms with similar features, can have a homogeneous appearance. This lack of visual diversity can make it challenging for the SLAM system to differentiate between different locations or correctly identify loop closures.
Unpredictable movements: Being a social robot, it is highly likely that the social interaction with the robot could interfere with its mapping and/or navigation process. SLAM algorithms are robustly built to mitigate such instances but nevertheless this could compromise the accuracy of the algorithm.
Addressing these challenges often requires the development of robust feature extraction methods, sophisticated tracking algorithms, sensor fusion techniques (such as incorporating depth sensors or IMUs), adaptation to changing lighting conditions, and handling occlusions. Additionally, leveraging prior knowledge of the environment or incorporating additional sensors can enhance the performance and reliability of indoor navigation with visual SLAM.
Social Bots versus Robot Vacuums
Mapping the environment for companion or social bots is more challenging compared to robot vacuums due to the dynamic and complex environments they operate in, higher interaction requirements, varied task capabilities, user-centric adaptability, and the need to ensure safety and social considerations during navigation. Robot vacuums can map their surroundings while doing a sweeping/mopping pass as they are usually undisturbed. On the other hand, environment mapping in social robots is much harder as they operate in uncontrolled settings and require advanced perception and understanding capabilities to interact with objects and people. They require personalized mapping to adapt to individual user preferences and provide a range of tasks beyond navigation and cleaning. A robot could be picked up and displaced during the process of map building. Social bots also experience greater wear and tear of the camera lenses, sensors and wheel encoders and this can affect the integrity of the SLAM.Last but not least, the technology used for SLAM has to be cost-effective to meet the price point consumers are willing to pay.
Self-navigation Framework in Miko
At Miko, we are working on integrating Visual Inertial SLAM for our future generation of companion robots to address the above challenges. Visual-Inertial SLAM combines visual sensor data from cameras with inertial measurements from an IMU (Inertial Measurement Unit). By fusing information from both sensors, visual-inertial SLAM achieves accurate and robust estimation of the robot's pose and creates a map of the environment. It leverages visual features for detailed environment perception and integrates inertial measurements for robust motion estimation, making it valuable for applications such as robotics, augmented reality, autonomous vehicles, and virtual reality.
Visual-Inertial SLAM typically involves the following steps:
Sensor Calibration: Calibrate the camera and IMU for accurate measurements.
Initialization: Establish an initial pose estimate using visual features and inertial data.
Feature Tracking and Inertial Odometry: Track visual features and estimate robot motion using inertial measurements.
Visual-Inertial Fusion: Fuse visual and inertial data for optimized pose estimation.
Mapping: Construct a map using tracked features and estimated poses.
Loop Closure Detection and Map Optimization: Identify revisited locations for error correction and refine poses and feature positions for better map consistency.`
Localization and Mapping Updates: Continuously update poses, map, and incorporate new data.
These steps provide a concise overview of the iterative process in Visual-Inertial SLAM, covering the calibration, initialization, motion estimation, fusion, mapping, loop closure, optimization, and continuous updates involved in simultaneous localization and mapping.
A block diagram of visual inertial SLAM is shown in Figure 2.
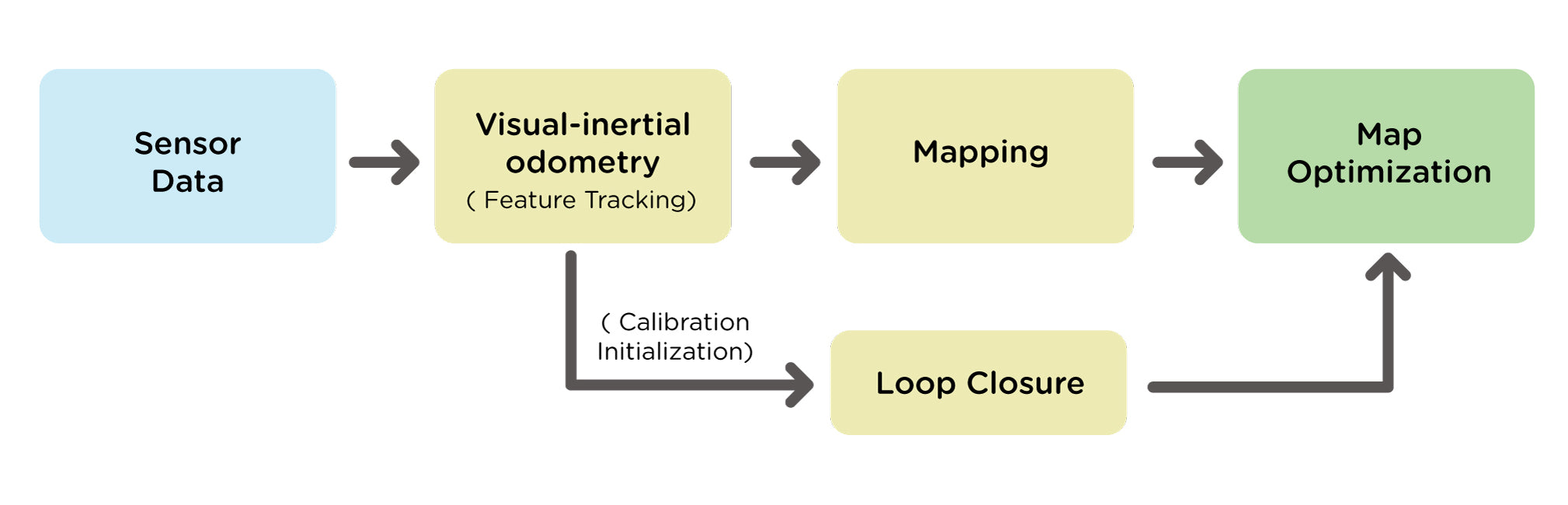
Miko uses a monocular camera, Inertial Measurement Unit (IMU) and wheel encoders to capture data that is abstracted into models. Successive frames from the monocular camera, coupled with gyroscope (angular velocity along the three axes) readings from the IMU, is used to estimate the camera pose, detect landmarks and track movement through visual inertial odometry (VIO) (see Figure 3). In addition, the wheel encoder (Miko uses a magnetic quadrature encoder) is used to determine the linear (along x, y axes) and angular (about z axis) displacement of the robot by counting the rotations of the wheels and this information is used to optimize and correct the VIO pose estimate for appropriate depth and scale.

The back-end filters and reconstruction stages (see Figure 3) refine the VIO output to generate fully optimized robot trajectories and a detailed occupancy grid map (shown in Figure 4). The occupancy grid map is used to understand the environment and navigate the robot. Loop closing performs corrections and removes accumulated drifts by estimating if the robot has come back to its original position.

Figure 4: 2D Occupancy Grid: occupied grid-points are black, unoccupied are white and unknown grid-points are gray (Creative Commons — Attribution 4.0 International — CC BY 4.0)
Summary
SLAM (Simultaneous Localization and Mapping) technology has truly revolutionized the landscape of self-navigating indoor social bots. By harnessing the power of visual sensors and inertial measurements, these bots can navigate indoor environments, map their surroundings, and engage with humans in personalized and interactive ways. As SLAM techniques continue to advance, we can expect smarter bots with enhanced capabilities for educational and interactive engagements.
References
[1] Cadena, Cesar & Carlone, Luca & Carrillo, Henry & Latif, Yasir & Scaramuzza, Davide & Neira, Jose & Reid, Ian & Leonard, John. (2016). Simultaneous Localization And Mapping: Present, Future, and the Robust-Perception Age. IEEE Transactions on Robotics. 32. 10.1109/TRO.2016.2624754.
[2] Welcome to Basic Knowledge on Visual SLAM: From Theory to Practice, by Xiang Gao, Tao Zhang, Qinrui Yan and Yi Liu






